# ollvm 三种混淆模式反混淆
# 预备知识:
llvm 是一个完整的编译器架构,作用可以理解为制作一个编译器,llvm 先将源码生成为与目标机器无关的 LLVMIR 代码,然后把 LLVMIR 代码先优化,再向目标机器的汇编语言而努力。经典编译器都可分为前端、中层优化和后端:
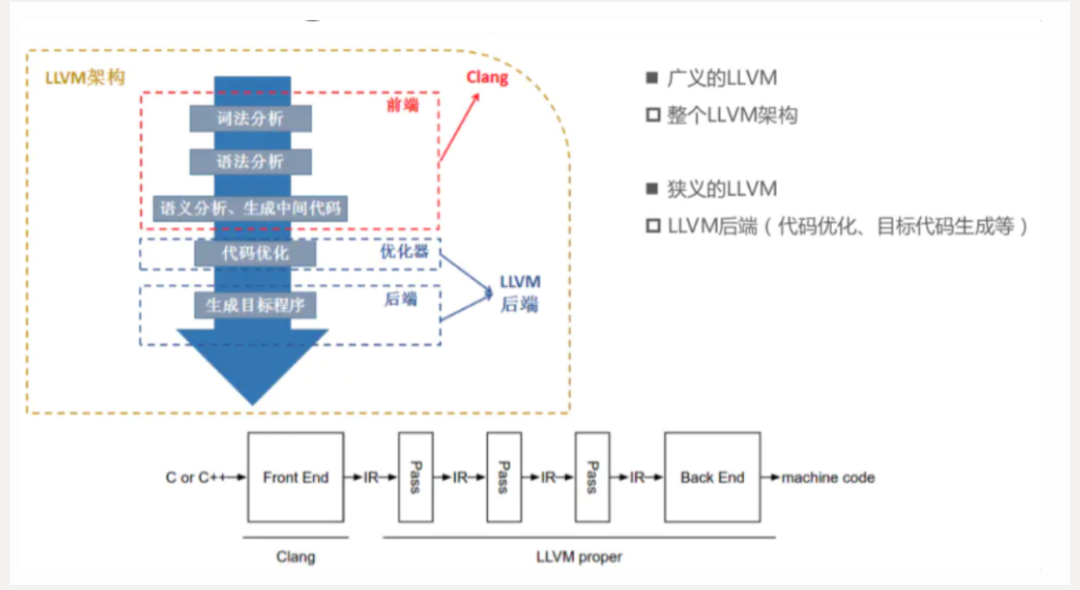
从上图中可以看到 clang 是前端的一个套件,但在实际使用时,我们只可以感受到 clang,也只是在使用 clang,因为编译的时候,是调用 clang 或 clang++ 来编译源码。
而 ollvm 是基于 LLVM 代码分支的代码混淆,在中间表示 IR 层,通过编写 pass(遍历一遍 IR,可以同时对它做一些操作)来混淆 IR,这样目标机器的汇编语言也就被混淆了。
# (1)虚假控制流 BCF (Bogus Control Flow)
# 原理
虚假控制流混淆通过加入包含不透明谓词的条件跳转(也就是跳转与否在运行之前就已经确定的跳转,但 IDA 无法分析)和不可达的基本快,来干扰 IDA 的控制流分析和 F5 反汇编。
所谓的不透明谓词,例如:
1 | if(x>10 && x<=10){ |
对于这类表达式,可以很明显的看到, x>10 && x<=10 是永假式,所以 goto Label1 这个跳转永远不会执行,但是对于 IDA 来说可不是这个样子,在静态分析的时候,IDA 并不知道 x 的值是多少,所以说这类虚假控制流就会干扰我们的静态分析。
# ollvm 的 BCF 混淆
使用下列命令对代码进行 BCF 混淆
1 | clang -mllvm -bcf -mllvm -bcf_loop=3 -mllvm -bcf_prob=40 test.c -o test-bcf |
可用选项:
-mllvm -bcf :激活虚假控制流
-mllvm -bcf_loop=3 : 混淆次数,这里一个函数会被混淆 3 次,默认为 1
-mllvm -bcf_prob=40 : 每个基本快被混淆的概率,这里每个基本块被混淆的概率为 40%,默认为 30%
——————————————————————————————————————————————————
可以发现在 BCF 混淆之后,函数的控制流明显复杂了许多
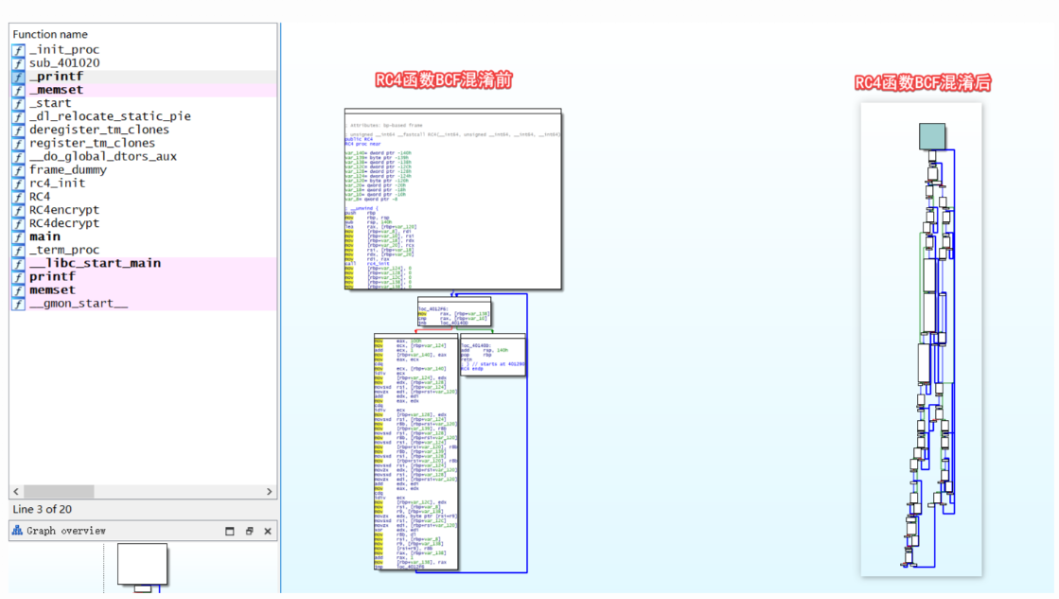
打开 BCF 混淆之后 IDA 的伪代码,发现多了许多 while,if 表达式,伪代码变得十分复杂,也让我们无法一眼看出这是何种加密。
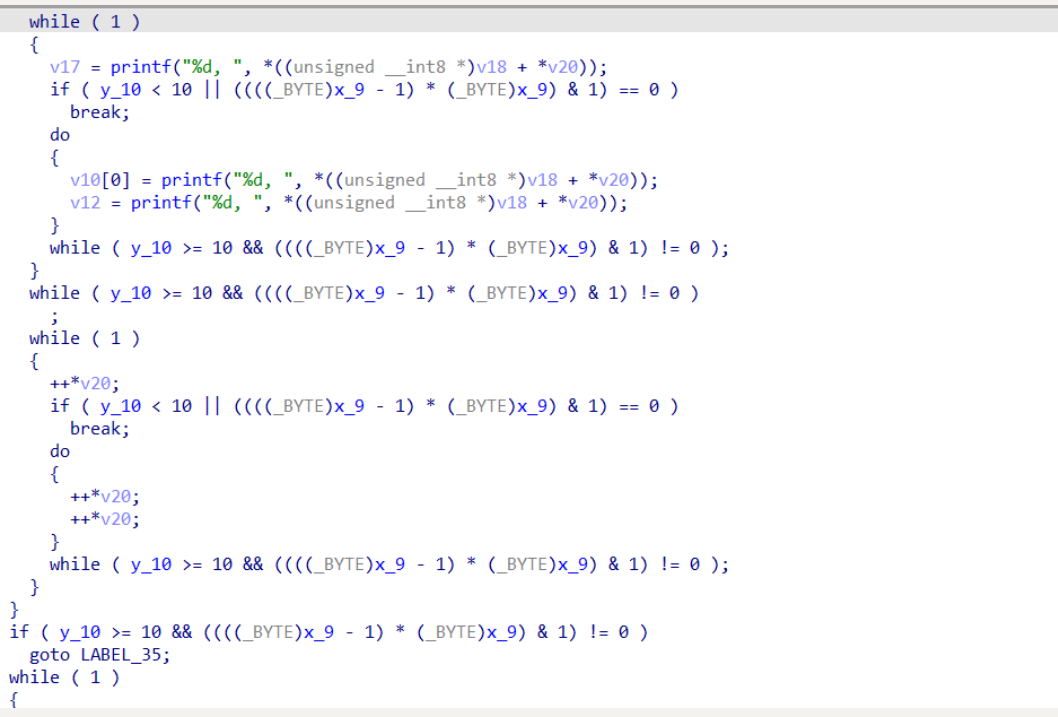
# ollvm 的 BCF 反混淆
我们往上看 while 内的表达式 y_10 >= 10 && (((x_9 - 1) * x_9) & 1) != 0 ,在这个式子中,
(x_9 - 1) * x_9) 的值永远是偶数,所以 (x_9 - 1) * x_9) & 1 永远返回 0,不等号左边
y_10 >= 10 && (((x_9 - 1) * x_9) & 1) 因为是用 && 作为连接词,所以左侧的表达式其实为永假式,
y_10 >= 10 && (((x_9 - 1) * x_9) & 1) != 0 永远不成立。
对于 BCF,有 3 种思路可以帮助我们进行反混淆
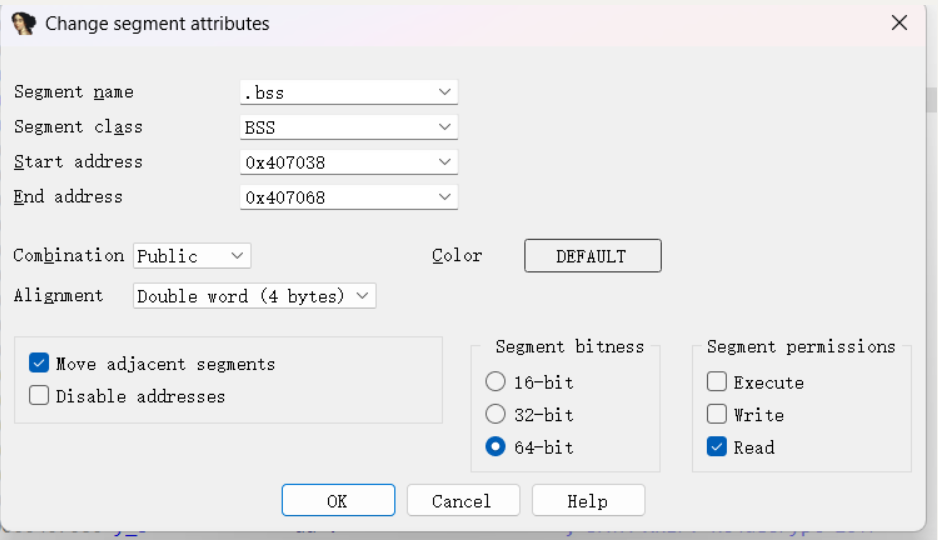
# 思路一:将全局变量赋值并将 segment 设为只读
但是如果我们把这个变量的值定下来,并且将变量所在的 segment 设为只读 ,那这个变量的值在没运行前也变不了,IDA 不就可以自己算出来这个表达式的值是多少了嘛,这样哪些没有用的跳转 IDA 就可以自动优化了
所以我们先双击 x_9 跳转到 x_9 的地址

然后按下 Alt+S 或者 Edit->Segments->Edit segment... 来改变不透明谓词所在的 segment 的读写属性,如图将 write 复选框取消勾选, .bss 段就设为只读了。
光是这样还不够,因为.bss 中的变量还没有被赋过值,所以我们还要 patch 这个段来固定.bss 段内变量的值
当然一个变量一个变量去 patch 显然有些麻烦,所以我们可以直接编写 IDApython 脚本来实现一步到位的效果,并且对于常见的 ollvm 的 bcf 混淆来说,bcf 的不透明谓词都是处于.bss 段中。如果不透明谓词定义在其他段中,将 IDApython 中的代码做出相对应的修改即可:
1 | import ida_segment |
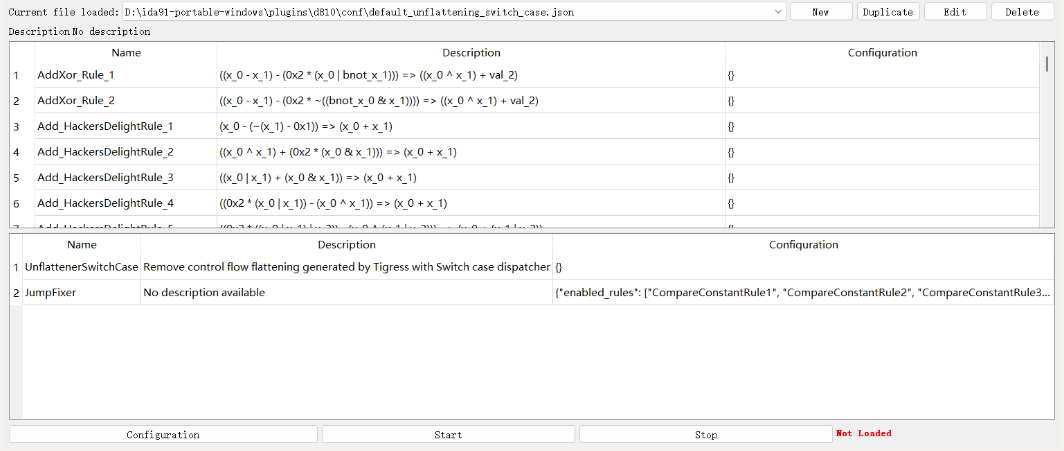
# 思路二:使用 d810 去除 BCF
d810 中内置了很多的不透明谓词表达式,他的匹配器也是非常的厉害完全可以做到去除虚假控制流
在 Edit->plugins->D-810 打开之后,选择 default_unflattening_switch_case.json
之后点击 start, 即可做到对不透明谓词的去除并还原控制流
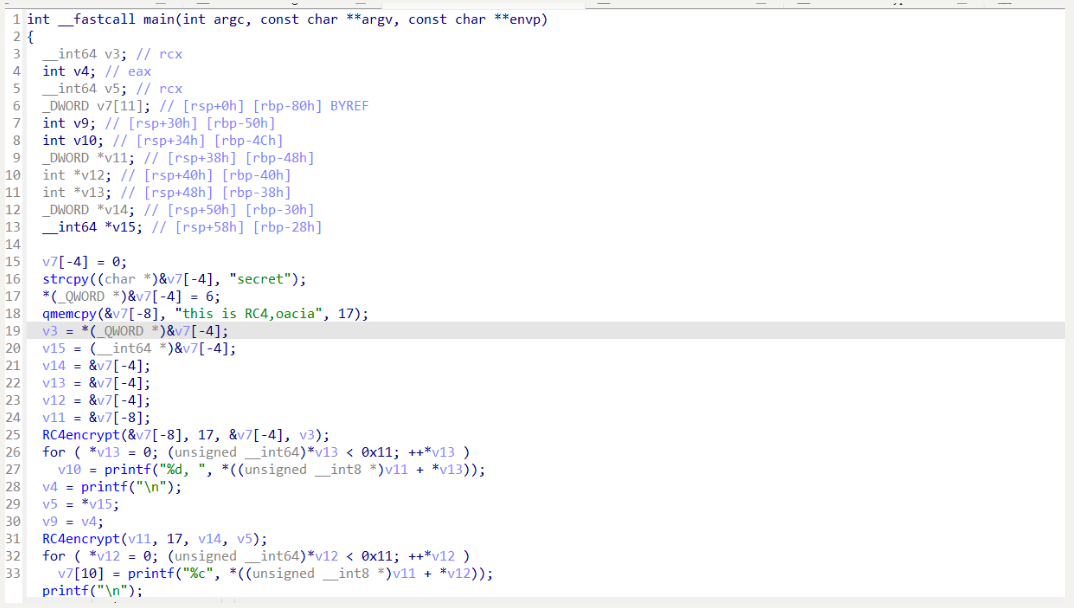
还原后的效果如下,可以发现和原本的代码基本是一样的:
# 思路三:使用 idapython patch 不透明谓词
在思路一中,我们通过对不透明谓词变量进行交叉引用找到了它们所在 segment,并通过将全局变量赋值并将 segment 设为只读的方法消除了 BCF,但是其实我们还可以用另外的一种方式去消除 bcf,就是在汇编中将不透明谓词直接 patch 掉
例如对于该不透明谓词 x_9 , y_10 , 它的 c 表达式为 y_10 >= 10 &&(((_BYTE)x_9 - 1) * (_BYTE)x_9 & 1) != 0
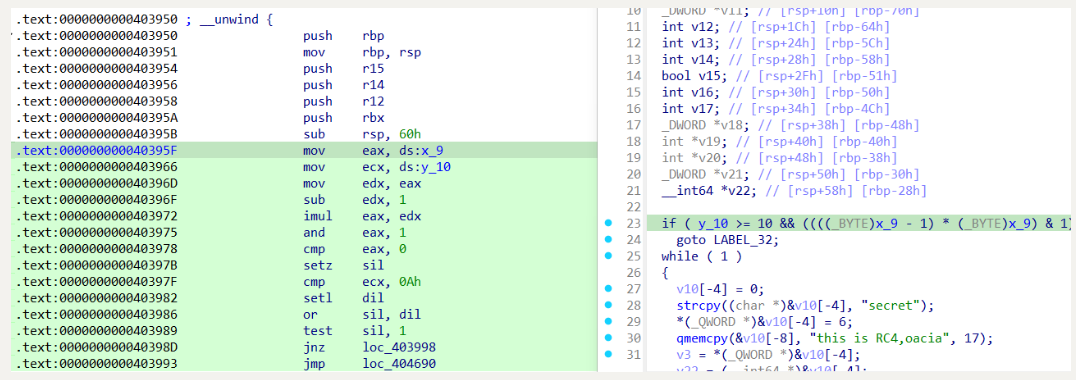
我们要做的就是让 mov eax, ds:x_9 改成 mov eax, 0 , 这样就可以做到消除 BCF 的目的
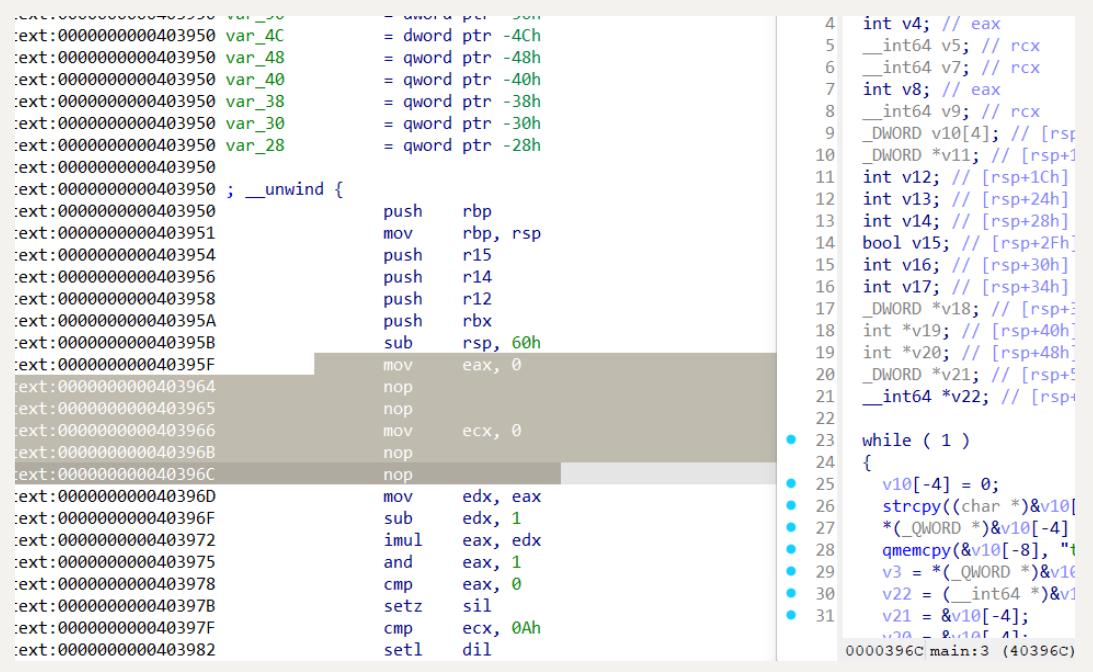
但是这样一个一个改过去显得十分的麻烦,所以我们可以用 ida python, 通过找到不透明谓词的所有交叉引用的方式来批量修改
1 | # 去除虚假控制流 idapython 脚本 |
这样 BCF 就被去掉了
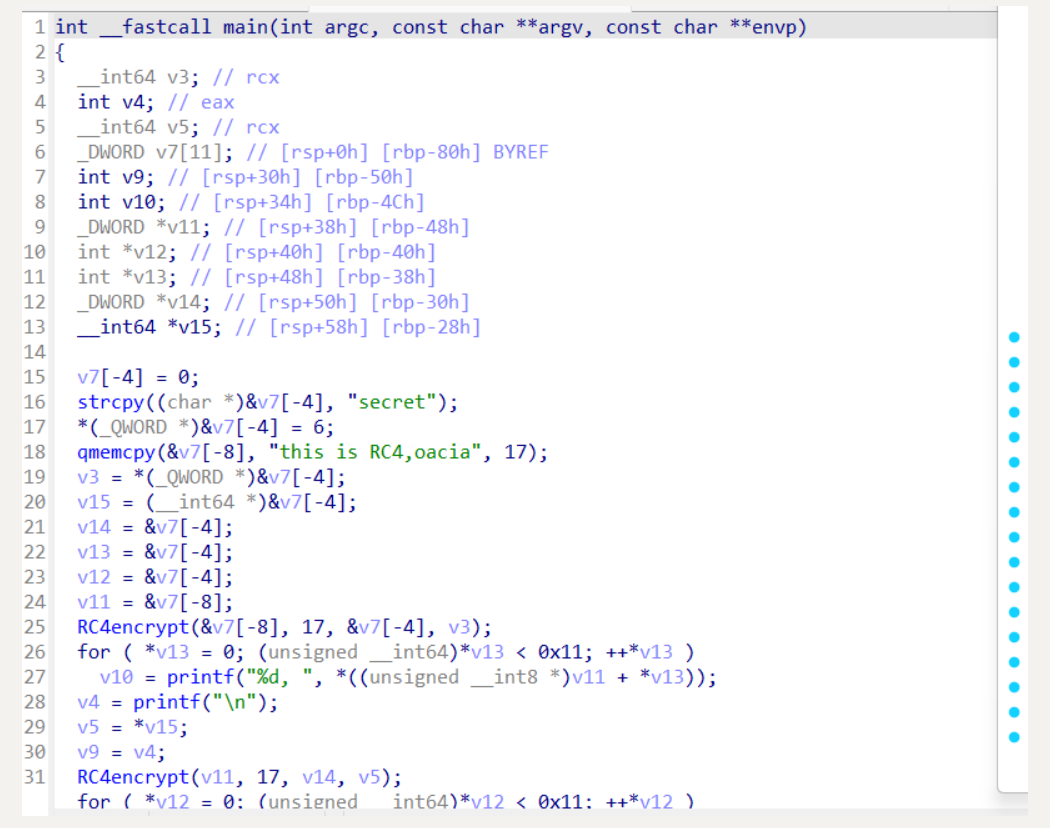
# (2)指令替换(SUB)
# 原理
指令替换(Instruction Substitution)是一种代码混淆技术,用于将程序中的原始指令替换为等效但更难理解和还原的指令序列。通过指令替换,可以增加程序的复杂性和抵抗逆向工程的能力。
它的本质其实就是数学公式的简化,例如 (x + y) - 2 * (x & y) -> x ^ y
# ollvm 的 SUB 混淆
使用下面的命令对代码进行 SUB 混淆
1 | clang -mllvm -sub -mllvm -sub_loop=3 test-sub.c -o test-sub |
可用选项
-mllvm -sub: 激活指令替换-mllvm -sub_loop=3: 混淆次数,这里一个函数会被混淆 3 次,默认为 1 次
经过指令替换后,代码明显变长了很多
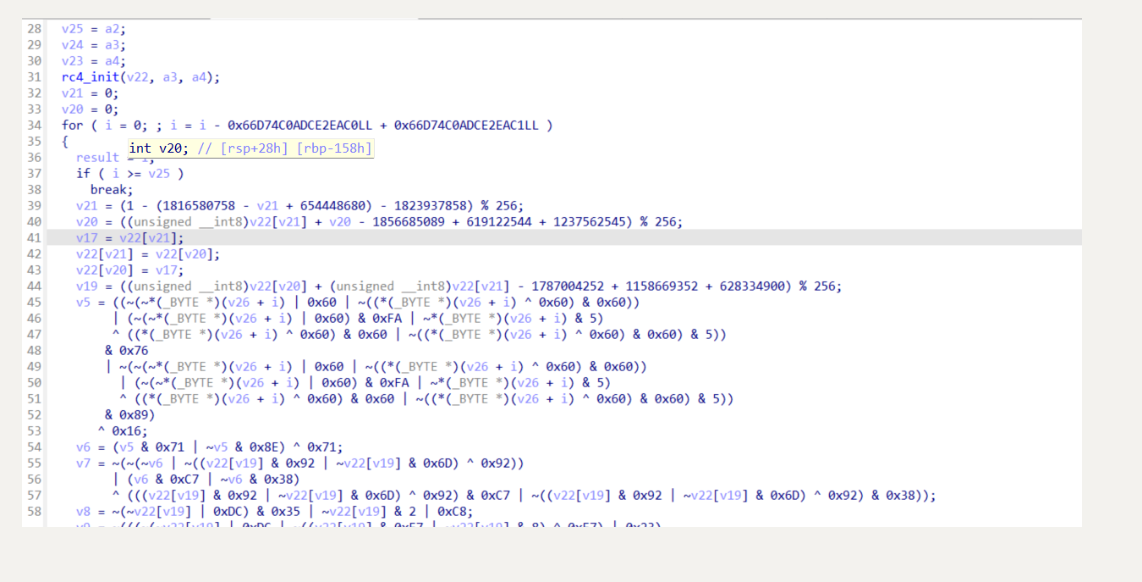
# ollvm 的 SUB 反混淆
# 思路一:使用 d810 去除 SUB
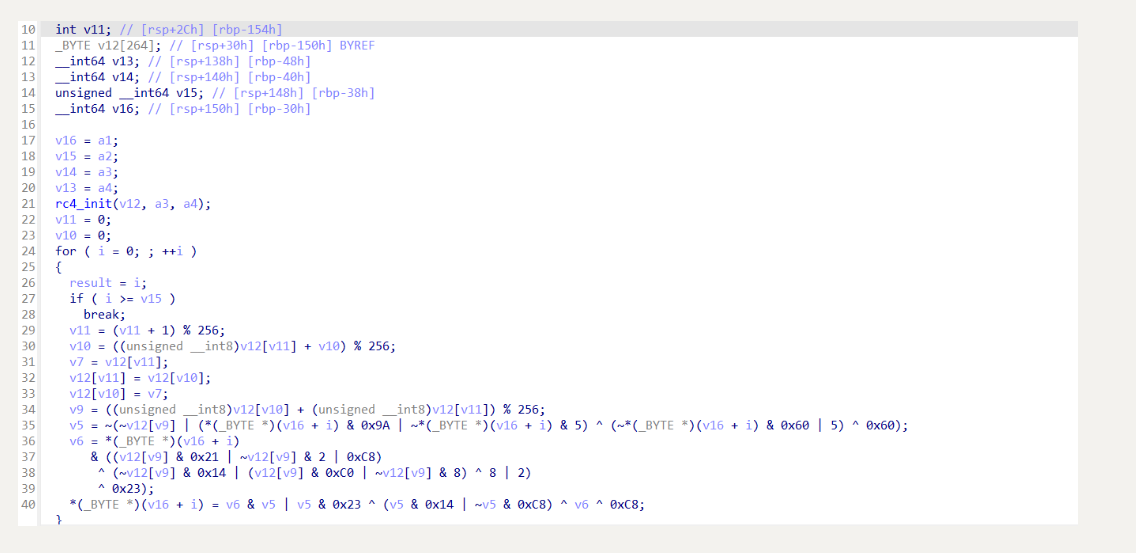
还是和去除 BCF 反混淆一样,直接跑一下 d810,虽然还是有一些部分没有去掉,但是看起来已经很清晰了,因为指令替换不影响程序整体的执行逻辑
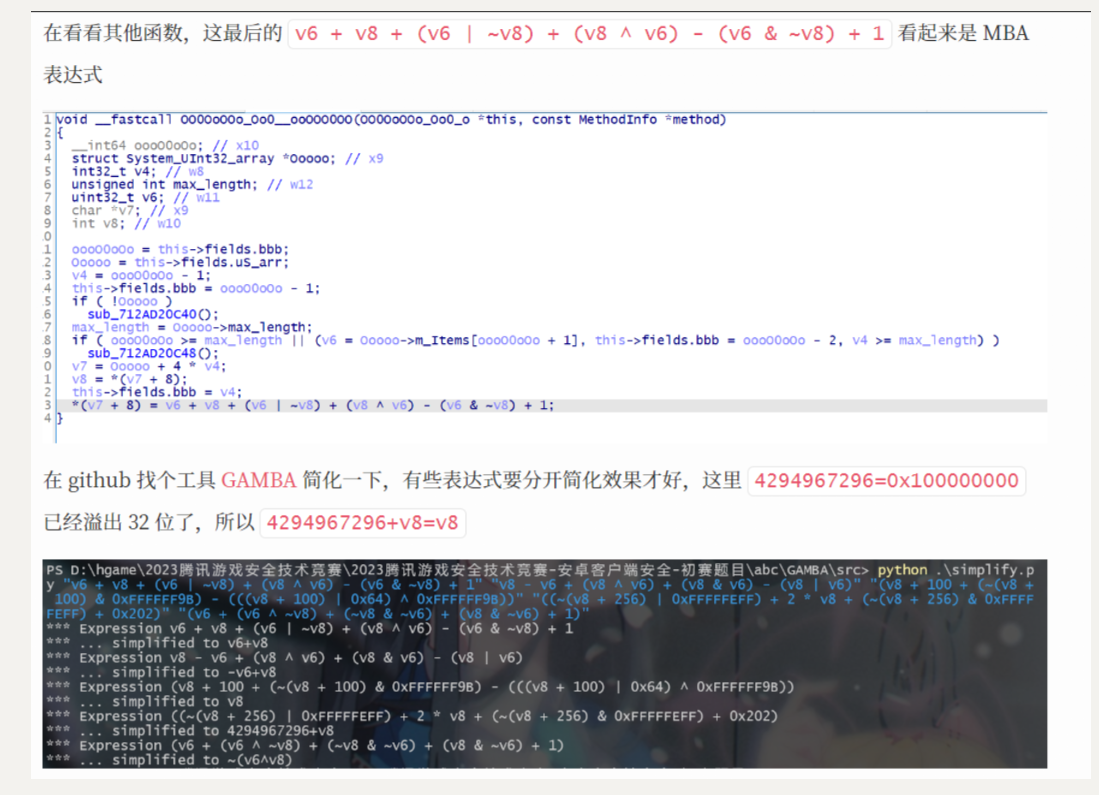
# 思路二:使用 GAMBA(通用高级混合布尔算术简化器)简化复杂的 SUB 表达式
这个思路二其实就是思路一那一点点未解决的 SUB 的补充,对于一些复杂的表达式来说,github 上的开源工具 GAMBA 可以很好的帮助我们简化
具体可以参考细品 sec2023 安卓赛题 中的加密三 vm 指令分析
# (3) 控制流平坦化 (FLA)
# 原理
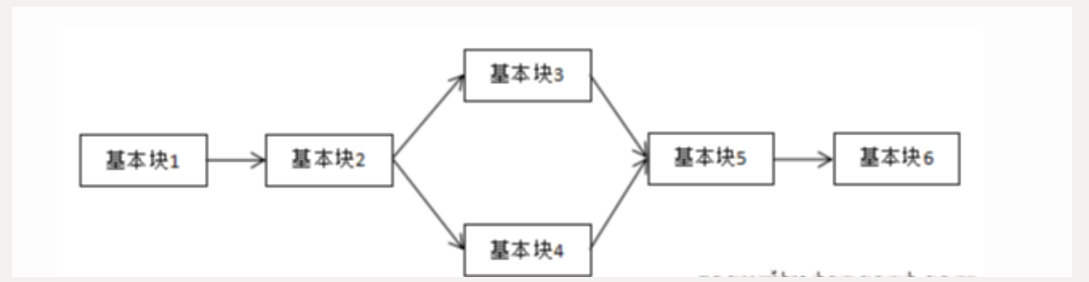
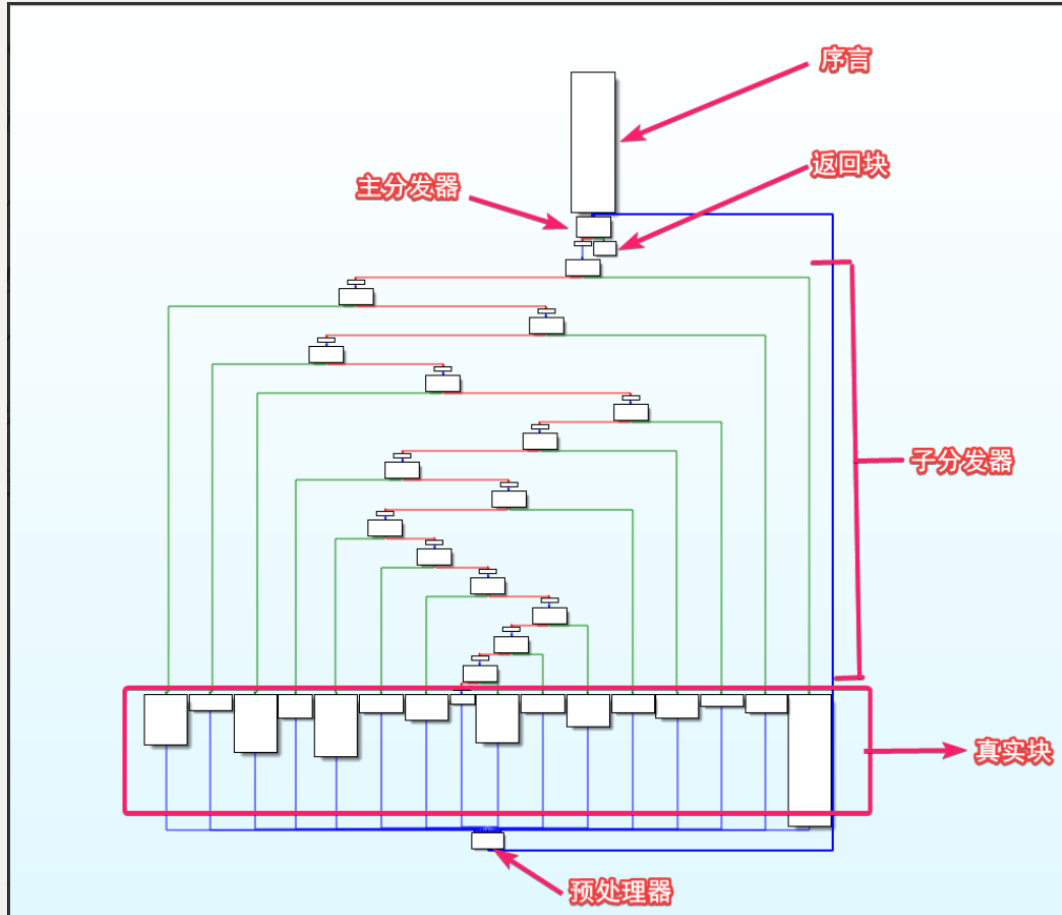
控制流平坦化(control flow flattening)的基本思想主要是通过一个主分发器来控制程序基本块的执行流程,例如下图是正常的执行流程
经过控制流平坦化后的执行流程就如下图
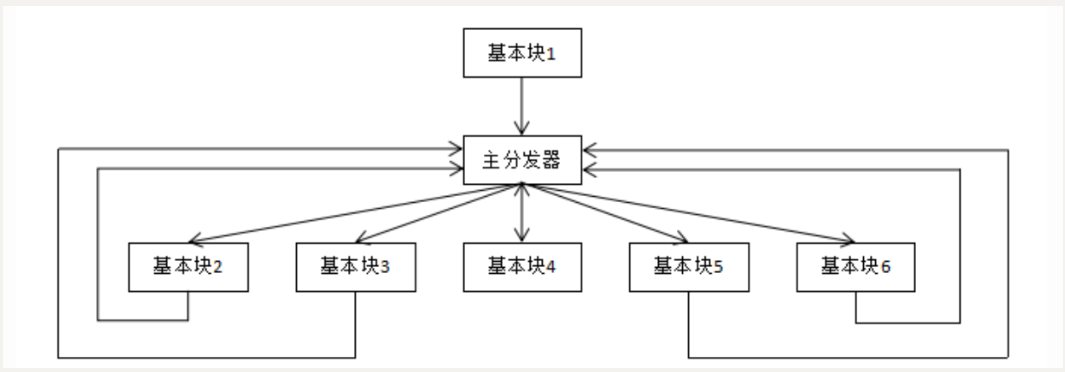
这样可以模糊基本块之间的前后关系
此图是一个经典的控制流平坦化 CFG
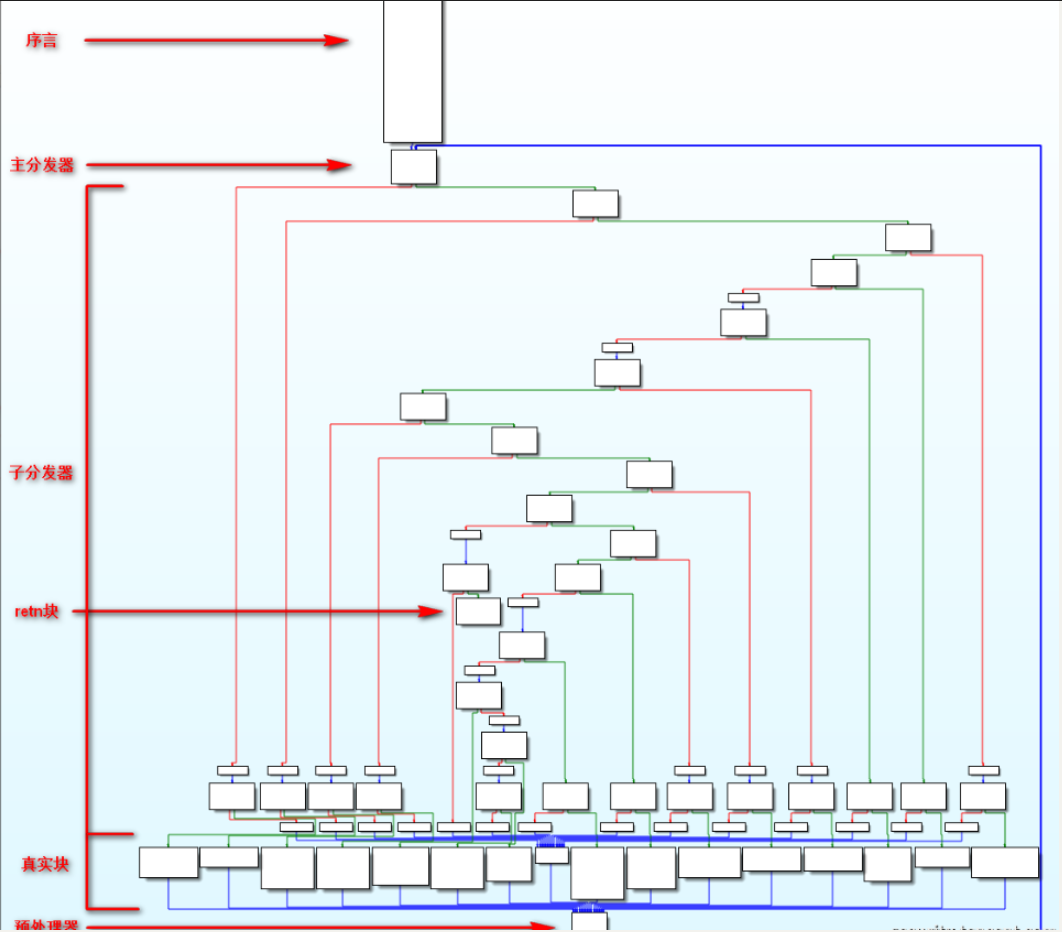
其中
- 序言:函数的第一个执行的基本块
- 主(子)分发器:控制程序跳转到下一个但执行的基本块
- retn 块:函数出口
- 真实块:混淆前的基本块,程序真正执行工作的块
- 预处理器:跳转到主分发器
#
# ollvm 的 FLA 混淆
使用如下命令即可完成 fla 混淆
1 | clang -mllvm -fla -mllvm -split -mllvm -split_num=3 test-fla.c -o test-fla |
可用选项:
-mllvm -fla: 激活控制流平坦化
-mllvm -split: 激活基本块分割
-mllvm -split_num=3: 指定基本块分割的数目
经过控制流平坦化之后,函数的逻辑已经很难看清了
![31]()
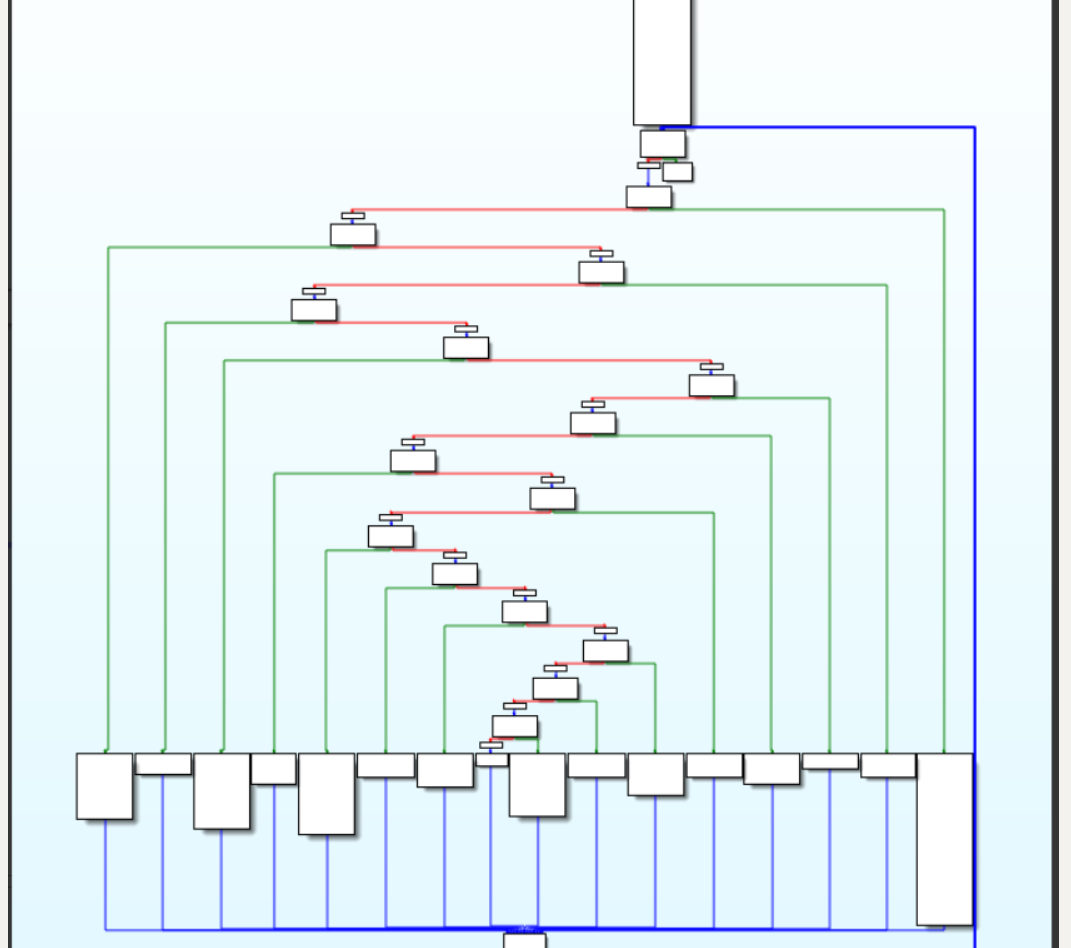
# ollvm 的 FLA 反混淆
想要定位各个块其实很简单,对于经典的 ollvm 来说,各个块之间有如下规则
- 找到序言块 ,这是整个函数的入口
- 序言块的后继是主分发器
- 主分发器的前驱有两个,除了序言块外,另一个块就是预处理器
- 预处理器的前驱是真实块
- 除此之外的其他块是子分发器
想要反控制流平坦化,我们只需要做 3 步
找到真实块。可以手动找真实块;可以用 idapython 通过各个块之间的练习通过一定的规则找真实块;可以用 unicorn 或 angr 得到函数的 CFG,利用规则匹配出真实块... 方法多种多样,但是核心都是找到真实块,除真实块和序言块外,其余的块都是虚假块,我们需要 nop 掉他们。
得到真实块之间的联系。我们主要想知道分支跳转的另一个分支,它究竟跳到了什么地方去的呢?所以这一步我们必须让代码运行起来,它把控制流给混淆了,我们要是不把代码跑起来咋知道控制流嘞?可以用模拟执行,也可以在真机调试打断点 trace, 核心都是为了找到真实块之间的调用关系。
得到了真实块之间的联系之后,我们只需要在每个真实块的末尾,用跳转汇编指令将每个真实块像串糖葫芦一样串起来,控制流平坦化就修复好啦
所以开始我们的第一步找到真实块和虚假块,对于标准的 ollvm 来说,观察得知预处理器的前驱都是真实块,所以我们写出如下的 idapython 脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import idaapi
import idc
target_func = 0x401E80#需要反控制流平坦化的函数的地址
Preprocessor_block = 0x402697#ollvm 中预处理器的地址,这个是通过观察 ida 中的 CFG 得到的,预处理器的前驱都是真实块
True_blocks = []#真实块列表
Fake_blocks = []#所有块的列表
f_block = idaapi.FlowChart(idaapi.get_func(0x401E80), flags=idaapi.FC_PREDS)
for block in f_block:
if block.start_ea==Preprocessor_block:#预处理器块的前驱都是真实块
#but 预处理器是虚假块
Fake_blocks.append((block.start_ea,idc.prev_head(block.end_ea)))
print("find ture block!")
tbs = block.preds()
for tb in tbs:
#print (hex (tb.start_ea),hex (idc.prev_head (tb.end_ea)))# 获取块的开始 / 结束地址
True_blocks.append((tb.start_ea,idc.prev_head(tb.end_ea)))
elif not [x for x in block.succs()]:#返回块没有后继
print("find ret block!")
True_blocks.append((block.start_ea,idc.prev_head(block.end_ea)))
# 序言块不作为虚假块处理
elif block.start_ea!=target_func:
#print(hex(block.start_ea),hex(idc.prev_head(block.end_ea)))
Fake_blocks.append((block.start_ea,idc.prev_head(block.end_ea)))
print('true block:')
print('tbs =',True_blocks)
print('fake block:')
print('fbs =',Fake_blocks)之后就是要得到真实块之间的联系啦,这里我使用 unicorn 来模拟执行得到真实块的调用关系,这里要注意的是因为我们只对一个函数中真实块的前后调用进行模拟执行,所以是不需要跳转到其他函数中的,遇到 call 指令直接将 pc 强制改成下一行汇编的地址,同时也要注意内存访问异常的情况直接通过
uc.hook_add(UC_HOOK_MEM_UNMAPPED|UC_HOOK_INTR, hook_mem_access)进行忽略通过这个 unicorn 脚本模拟执行,我们得到了分支跳转时下一个要跳转的真实块地址,以及此时的 ZF 标志位,这个标志位可是有着大用,通过这个标志位我们就可以知道究竟是 jz 跳转还是 jnz 跳转啦
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90# code for test-fla.elf
from unicorn import *
from unicorn.x86_const import *
from keystone import * # pip install keystone-engine
from capstone import * # pip install capstone
# import networkx as nx #pip install networkx
# import matplotlib.pyplot as plt # pip install matplotlib
BASE = 0x400000
CODE = BASE + 0x0
CODE_SIZE = 0x100000
STACK = 0x7F00000000
STACK_SIZE = 0x100000
FS = 0x7FF0000000
FS_SIZE = 0x100000
ks = Ks(KS_ARCH_X86, KS_MODE_64) # 汇编引擎
uc = Uc(UC_ARCH_X86, UC_MODE_64) # 模拟执行引擎
cs = Cs(CS_ARCH_X86, CS_MODE_64) # 反汇编引擎
# g=nx.Graph ()# 创建空的无向图
# g=nx.DiGraph ()# 创建空的有向图
tbs = [(4204176, 4204182), (4203066, 4203066), (4203071, 4203098), (4203103, 4203157), (4203162, 4203314),
(4203319, 4203341), (4203346, 4203366), (4203371, 4203398), (4203403, 4203428), (4203433, 4203457),
(4203462, 4203490), (4203495, 4203514), (4203519, 4203558), (4203563, 4203585), (4203590, 4203609),
(4203614, 4203636), (4203641, 4203651), (4203656, 4203689), (4203694, 4203737), (4203742, 4203776),
(4203781, 4203804), (4203809, 4203831), (4203836, 4203856), (4203861, 4203888), (4203893, 4203918),
(4203923, 4203957), (4203962, 4203981), (4203986, 4204025), (4204030, 4204040), (4204045, 4204067),
(4204072, 4204091), (4204096, 4204118), (4204123, 4204133), (4204138, 4204171)]
tb_call = []
main_addr = 0x00000000000401E80
main_end = 0x0000000000040269C
def hook_code(uc: unicorn.Uc, address, size, user_data):
# print(hex(address))
for i in cs.disasm(CODE_DATA[address - BASE:address - BASE + size], address):
if i.mnemonic == "call": # 因为只是针对单个函数的控制流,所以我们并不需要跳转到其他的函数里面
print(f"find call at {hex(address)}, jump...")
uc.reg_write(UC_X86_REG_RIP, address + size)
elif i.mnemonic == "ret":
print("find ret block, emu stop~")
uc.emu_stop()
print("block emu path↓↓↓↓")
print(tb_call)
# for i in range(len(tb_call)-1):
# g.add_edge(tb_call[i],tb_call[i+1])
# Plot it
# nx.draw(g, with_labels=True)
# nx.write_gml(g,'./test-fla.gml')
for tb in tbs:
if address == tb[1]:
# print (uc.reg_read (UC_X86_REG_FLAGS))#ZF 标志位在第 6 位
ZF_flag = (uc.reg_read(UC_X86_REG_FLAGS) & 0b1000000) >> 6
#print("ZF=", ZF_flag)
tb_call.append((tb, ZF_flag))
break
def hook_mem_access(uc: unicorn.Uc, type, address, size, value, userdata):
pc = uc.reg_read(UC_X86_REG_RSP) # UC_ARM64_REG_PC
print('pc:%x type:%d addr:%x size:%x' % (pc, type, address, size))
# uc.emu_stop()
return True
def inituc(uc):
uc.mem_map(CODE, CODE_SIZE, UC_PROT_ALL)
uc.mem_map(STACK, STACK_SIZE, UC_PROT_ALL)
uc.mem_write(CODE, CODE_DATA)
uc.reg_write(UC_X86_REG_RSP, STACK + 0x1000)
uc.hook_add(UC_HOOK_CODE, hook_code)
uc.hook_add(UC_HOOK_MEM_UNMAPPED | UC_HOOK_INTR, hook_mem_access)
def init_graph():
for tb in tbs:
g.add_node(tb[1])
with open('./test-fla', 'rb') as f:
CODE_DATA = f.read()
inituc(uc)
try:
uc.emu_start(main_addr, main_end)
except Exception as e:
print(e)之后再去写一个 idapython 脚本将真实块串起来就可以啦,对于无分支跳转,可以直接将前后基本块通过 jmp 进行连接,而麻烦的只是分支跳转,我们由模拟执行后已经得到了分支跳转时的 ZF 标志位,通过该标志位我们将将 jmp 改成为零跳转 (jz) 亦或是非零跳转 (jnz)
![33]()
![34]()
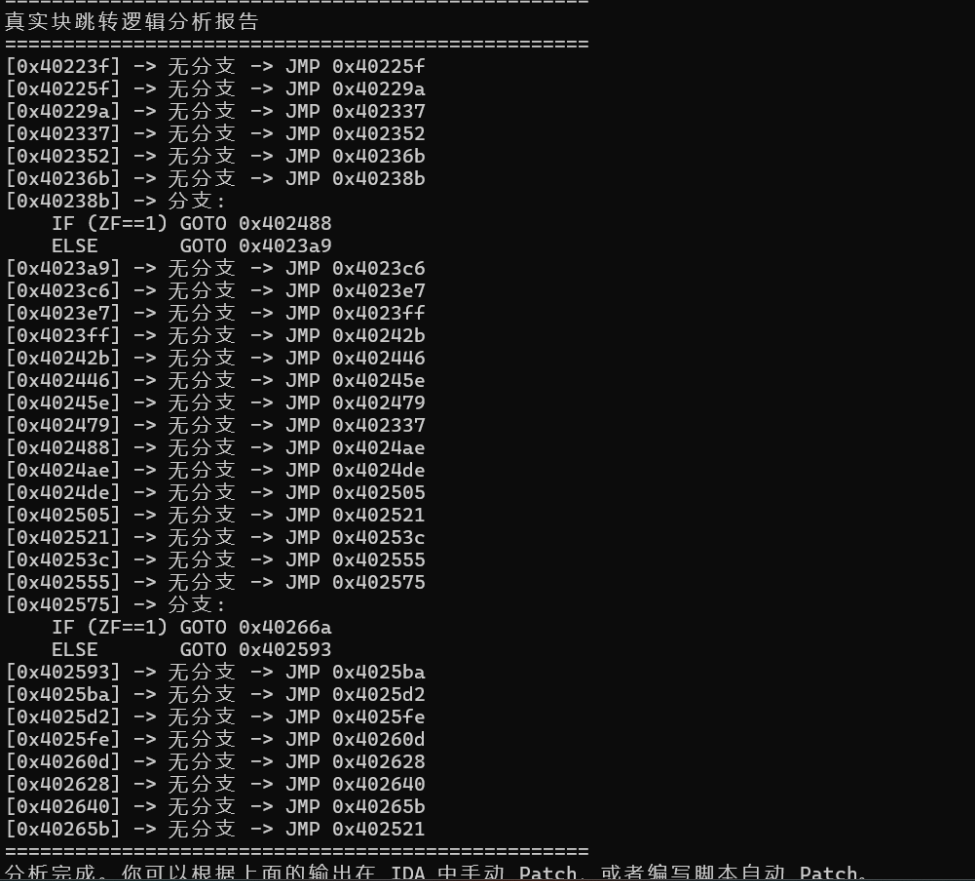
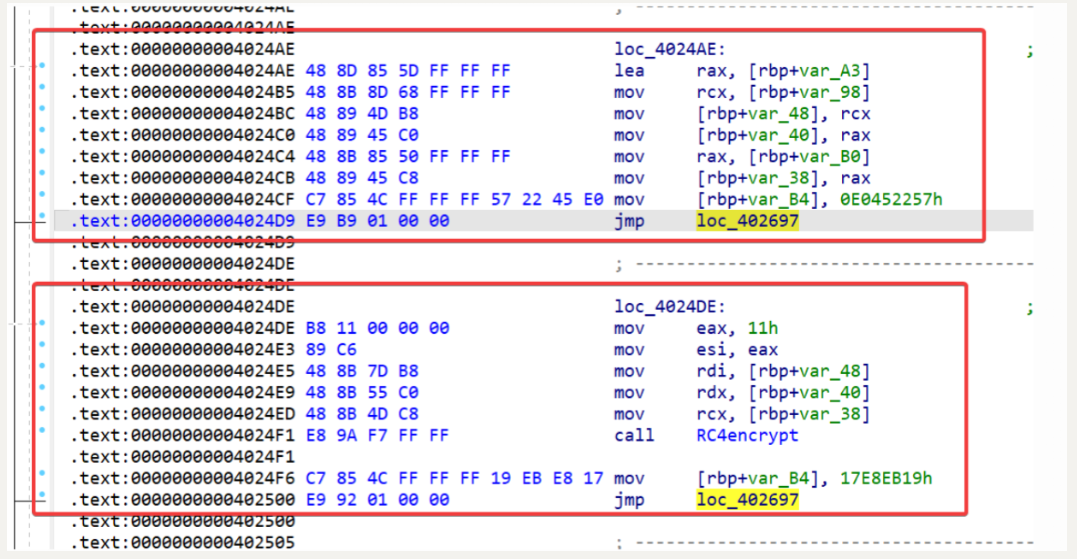
写一下 patch 脚本,修复成功~
1 | import idaapi |
patch 完之后看一下,这个代码也太好看了吧哈哈哈!
以上就是我对于 ollvm 混淆的一些总结😊😊